













INTRODUCTION
Feeding behavior represents the welfare and health status of pigs, so it provides adequate information to evaluate economic implications [1–3]. Several studies have reported that pig feeding behavior can be affected by diseases [4,5], environmental factors [1,3], and management systems [2,6]. Providing adequate water and feed increases the performance of farm animals and the frequency of use of feeders and drinkers. Aditionally, the amounts of water and feed intake are determinant factors representing health status, environmental changes, and feed delivery interruptions [7]. For instance, a sudden decrease in water consumption (20% to 30%) is an indicator of swine influenza outbreaks [8]. Currently, onsite and offsite visual monitoring is the most common procedure for evaluating pig behavior. In terms of accuracy and practicality, manual observation is a simple way to analyze the behavior of animals on small scale. However, manual detection is often time-consuming and laborious on a large scale sizes, particularly when there are several behaviors to be detected. Therefore, there is a need to develop automatic detection methods capable of handling large numbers of animal.
Several researchers have previously investigated computer-based systems for monitoring animal behavior based on image analysis [9–11]. Image processing is a non-invasive and practical technique for evaluating pig behavior over a long period of time. The evaluation of feeding and drinking behaviors has mainly been studied for large or restricted animals such as sows, finishing pigs, and cattle [4,11,12] because the recognition of large animals is easier than that of small and active animals. Experiments targeting the behavior of pigs have used body-part-based identification [13,14] or whole-body-based identification [11,15]. It has been reported that in both body-part-based identification and whole-body-based identification, tracking algorithms for pigs begin by designing support maps to recognize pig segments in captured images and then construct a 5D Gaussian model to detect individual pigs in different positions [16]. Kashiha et al. [17] reported that a faster region-based convolutional neural network (CNN) pig detector is preferred for pig segmentation when pigs cluster together. Alameer et al. [18] used a GoogLeNet-based deep learning method to identify feeding pigs without relying on pig tracking, which can distinguish between feeding behavior and non-feeding behavior in pigs. Another study was conducted based on the CNN architecture Xception for targeting spatiotemporal features to detect the feeding positions of group-housed pigs [19]. Although several different machine learning systems have been tested for detecting behavioral factors in pigs, there is still a lack of reports regarding their accuracy for evaluating feeding frequency in group-housed pigs. However, several machine learning systems have been tested to detect behavior factors of pigs, there is still a lack of reports on their accuracy in evaluating feeding frequency in group-housed pigs. In this study, we analyzed a pig image dataset from a real farm. Real farm image acquisition is influenced by parameters such as distance, picture resolution, and low-quality illumination. Therefore, the goal of this study was to develop a you-only-look-once (YOLO)-based method to classify pig image datasets to predict the frequency and duration of feeding behaviors using a suitable classifier for processing data.
MATERIALS AND METHODS
This study was approved by IACUC of Rural Development Adminstration (No. NIAS-2021-538). In the collected pig cage data, there are defined categories for bounding boxes of pigs that drink water and pigs that eat feed. The labeled data were divided into training data and testing data and a detection model was trained based on the YOLO algorithm. The results of the trained model were evaluated using classification performance indicators.
Videos were recorded on a JSK swine commercial farm (Busan, South Korea). Group-based weanling pigs were considered in this study. The average body weight of the pigs was 6.3 ± 1.4 kg. The weaned pigs were crossbred from Landrace × Yorkshire and Duroc composite male lines. The pigs were solid white. Each pen was 3.55 m × 2.44 m in size and contained two feeder types, namely a round feeder (54 cm diameter) and trough feeder (1.8 m length), as well as a nipple drinker. Fig. 1 presents the locations and sizes of the feed bins and the water supplies installed in the pig cages. A camera was installed at a height of 1.88 m high from the bottom of the pig cage. The camera was a Sony HDR-AS50 with a resolution of 1920 × 1080 pixels at 30 fps. Four pig cages were monitored from 10 AM to 4 PM. Three of the four pig cages were considered as training data and the remaining cage was considered as testing data. The videos were converted into still images by keeping every 20th frame. A total of 139,040 images were obtained and the number of data labeled for drinking or feeding pigs was 9,880. There were 7,273 images in the training data and 2,607 images the testing data. In the training data, there were 1,906 pigs that drank water and 20,847 pigs that ate feed. In the testing data, 1,064 pigs drank water and 9,536 pigs eat ate. The data are summarized in Table 1. As shown in Fig. 2, water supply facilities and feed barrels combined with pig heads create boundary boxes for training. The pigs have two water supply facilities and one feed container. In the water supply facilities, only one pig can be supplied at a time, whereas the feeder can supply up to 10 pigs at a time. Therefore, up to two pigs can drink water and up to 10 pigs can eat feed simultaneously.

| Train | Test | |
|---|---|---|
| The number of image | 7,273 | 2,607 |
| The number of drinking pig | 1,906 | 1,064 |
| The number of eating pig | 20,847 | 9,536 |

A YOLO-based detection algorithm that is advantageous for the real-time monitoring of pig behavior was adopted. Three different algorithms were tested: YOLOv4, YOLOv3, and YOLOv3 with an added detection layer and modified activity function.
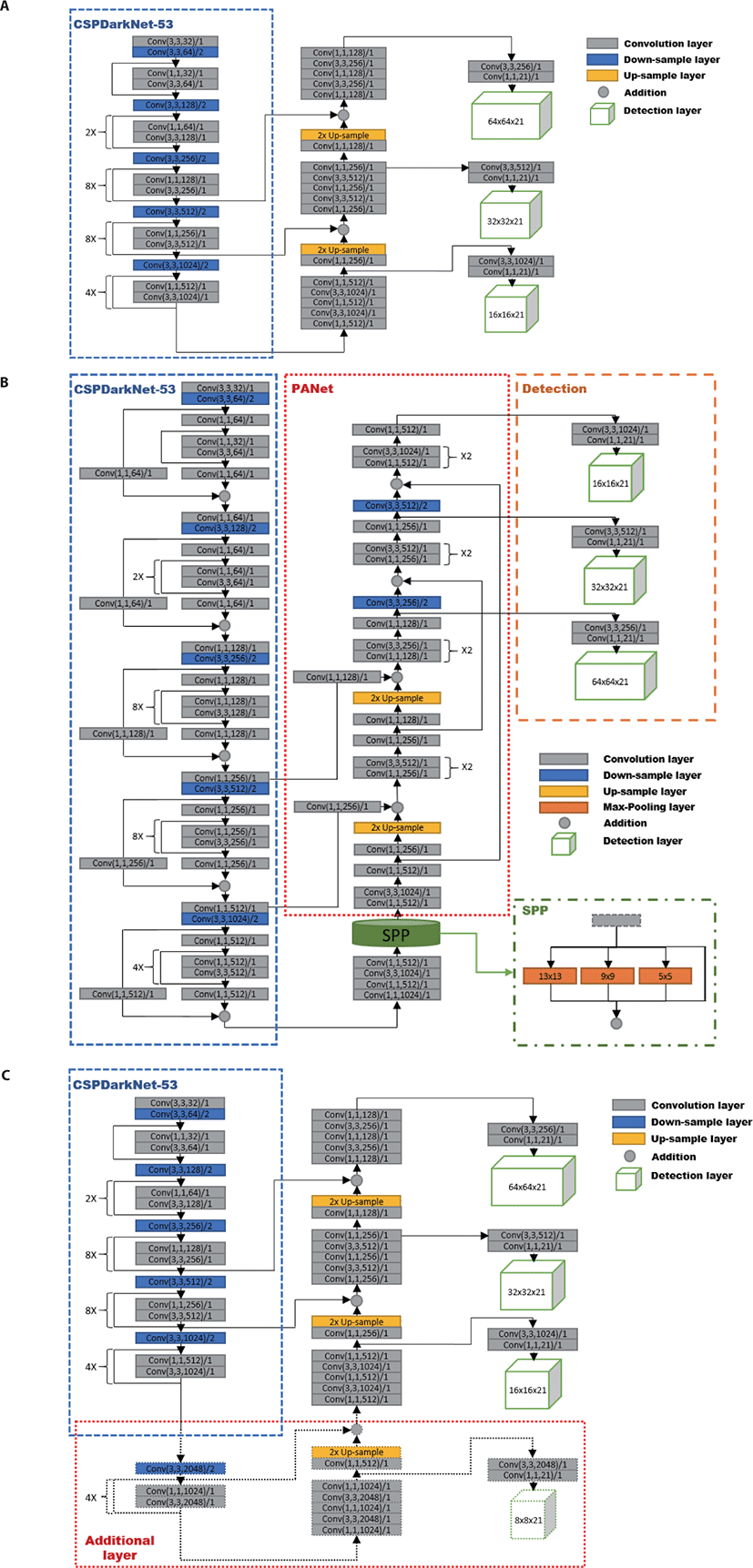
By using Darknet53 as a backbone network to extract features, continuous 3 × 3 convolutions, 1 × 1 convolutions, and shortcut layers can be used to construct deep networks and prevent overfitting. A feature map extracted by Darknet53 passes through a feature pyramid network (FPN). The FPN can learn from feature maps of three sizes using downsampling and upsampling. This is efficient because feature maps of various sizes can be used for learning one sample. Additionally, to reinforce the data lost during upsampling, each map can be combined with another feature map of the same size before downsampling.
The performance of YOLOv3 was analyzed based on image size. The image sizes (same width and height) were 320, 416, and 608 pixels, and the speeds were 22, 29, 51 ms, respectively, resulting in mean average precision (mAP) values of 51.5%, 55.3%, and 57.9%, respectively. In the YOLOv3 paper, the processing speed of the FPN-FRCN network, which achieved the highest mAP of 59.1%, was 172 ms. Compared to the slowest YOLOv3-608 network, the mAP is increased by 1.2 times, but the difference in processing speed is almost three times [20].
Unlike the previous YOLOv3 network, YOLOv4 can be trained using a single GTX 1080TI GPU and has improved accuracy. Compared to YOLOv3, the YOLOv4 network structure improves performance by using bag of freebies (BoF) and bag of specials (BoS) components. When comparing the performances of YOLOv3 and YOLOv4, YOLOv4 improves the processing speed by 8 fps and the mAP by 12.4% [21]. BoF represents a group of methods for increasing the performance by maintaining inference costs. The first method is a data augmentation method that increases performance by augmenting data using tools such as CutOut, which is a method for randomly setting a pixel value to zero in a specific part of an image, and CutMix, which mixes a specified part of an image with other random images. However, in this study, when this method was used, the loss rate did not converge to zero, but diverged. Therefore, the image augmentation and mosaic methods included in the default YOLOv4 model were not used. Additionally, as a strategy to prevent overfitting during learning, a method for randomly disconnecting layers or connecting the outputs of previous layers to subsequent layer was adopted during training. The methods used in this study were DropOut, DropPath, Spatial DropOut, and DropBlock. Additionally, a loss function is used to adjust predicted bounding boxes to be more similar to ground-truth bounding boxes. The dropout methods used were generalized intersection over union (GIoU), complete IoU, and distance IoU (DIoU).
BoS is a method for increasing performance by increasing inference costs. BoS uses six techniques: enhancement of receptive fields, feature integration, activation functions, attention modules, normalization, and post-processing. To enhance the receptive field, spatial pyramid pooling (SPP) and atrous SPP were adopted. For feature integration, skip connections and an FPN were used. The rectified linear unit (ReLU) series, Swish, and Mish were used as activation functions. The attention module uses a squeeze-and-excitation module and a spatial attention module, which increases the inference cost slightly, but improves performance. For normalization, we use batch normalization, filter response normalization, and cross-iterative batch normalization to slow learning progress and prevent overfitting. Finally, for post-processing, non-maximum suppression (NMS), soft NMS, and DIoU NMS, which represents one of the multiple overlapping bounding boxes in one object, are applied [22].
Fig. 3 presents the learning structure of the YOLOv4 model. A feature map is extracted from the backbone using the CSPDarknet53 network proposed by Alexey [22]. The neck plays the role of connecting the extracted feature map to the detection layer. Additionally, YOLOv4 uses a two-stage detector method. In one stage, the location of an object is determined and in the second stage, the object is classified [22].
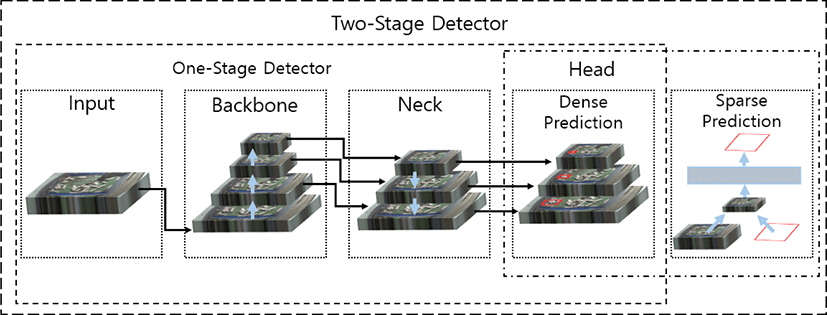
The proposed algorithm changes the detection layer and activation functions of YOLOv3. YOLOv3 learns and detects three image sizes through downsampling, but the proposed algorithm learns and detects a total of four sizes by adding an additional downsampling layer. This is a more efficient learning method because feature maps can be extracted from diverse sizes through one learning process. The replaced active function uses the Mish function. The original activation function was the leaky ReLU function, which leads to poor connectivity to the output because there is a distortion at the point where the input is zero. In contrast, the Mish function yields a smooth curve where the input is zero, so it is possible to deliver a stable value to the next layer input [23]. Fig. 4 summarizes the structures of YOLOv3, YOLOv4, and YOLOv3 with the proposed modifications.
To evaluate the results of pig behavior detection, classification performance indicators and mAP were adopted. The classification performance indicators are the precision, recall, and F1-Score, and mAP uses an IoU threshold value to determine results.
Precision represents the number of true positives among all positively predicted samples, as shown in the following equation:
Recall represents the number of true positives among all positive samples in the dataset and is expressed by the following equation:
The F1-Score is the harmonic average of precision and recall, and this average is derived by weighting the lower of the two values. This measure indicates reduced performance when the difference between precision and recall is large. The IoU represents the extent to which the ground truth overlaps the predicted bounding box for object detection, as shown below.
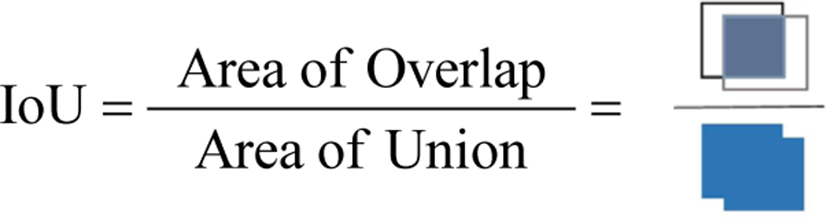
The mAP uses the IoU as a threshold to select bounding boxes that are above a certain threshold. The selected bounding boxes are sorted in descending order of their IoU values to draw a precision-recall curve. The area under the drawn curve is the mAP. mAP is an indicator of both identification and classification performance because the IoU, which represents location accuracy, and the precision-recall curve, which represents classification accuracy, are both considered.
RESULTS AND DISCUSSION
Because the health statuses of pigs can be determined based on their intake of feed and water, it is important to observe pigs continuously and check these intake levels. However, because humans cannot watch animals around the clock, technology for evaluating pig behavior based on recorded video is required. In this study, pig behavior was evaluated using YOLO, which is an object detection algorithm. Two behaviors were detected: drinking water and eating feed. Pig behavior detection identified a behavior corresponding to a class if the predicted bounding box overlapped by more than 50% with the relevant ground-truth bounding box. The networks used in this study were YOLOv3, YOLOv4, and a network in which additional layers and the Mish function were applied to YOLOv3. YOLOv3 uses the smallest amount of computing resources among the three networks and requires the smallest amount time to learn, but its performance is lower than that of the other two methods. YOLOv4 provides the best performance and fastest detection speed. However, it also uses the most computing resources. The modified YOLOv3 model incorporates an additional detection layer, so it has a longer detection time than the other networks, but it can detect pig locations better than YOLOv3 and requires fewer computing resources than YOLOv4. Additionally, the Mish function used in the modified network is a more complex activation function than the leaky ReLu function used in YOLOv3, so it uses more computing resources, but it also facilitates information flow inside the network and improves normalization performance to enhance feature extraction.
The considered IoU_threshold values were 0.5 and 0.6. In Table 2, when IoU_threshold is 0.5, the mAP values are greater than 90%. When IoU_threshold is 0.6, they fall to 73% to 77%. Additionally, the average IoU for each class is 0.72 for drinking water and 0.66 for eating feed. In Figs. 5 and 6, the actual number of pigs eating feed is large and the number of pigs drinking water is small. Additionally, the horizontal length of the water supply facility is similar to the size of a pig’s head and the boundaries of the water supply facility are clear, which facilitates a high IoU.


Recall appears to be lower than precision in Table 2 because the overlap for feeding pigs is worse than that for pigs drinking water based on the large number of pigs eating food. When pigs overlap, two or three pigs feeding are recognized as having an increased false negative rate. Fig. 7 presents the behavior of most feed-eating pigs, but one can see that the two pigs at the top of Figs. 7A and B are identified as a single pig. Fig. 7A presents pigs that overlap horizontally and Fig. 7B presents pigs that overlap vertically, as indicated by the red boxes. In contrast, in the water drinking row, only one pig can drink water per water supply tank, and their head is located in the water supply tank, so it is clearly distinguished from pigs that are not drinking water. The cause of the increase in false negatives is the NMS used to solve the duplicate detection of multiple boundary boxes in a single object. NMS leaves only one bounding box with high predictability among bounding boxes that overlap by more than 50% [22]. In Fig. 7A, the overlapping pigs are recognized as a single pig as a result of NMS. The lower the IoU, the greater the rate of overlap with surrounding pigs. Therefore, a high-IoU bounding box can reduce the chance of a false negative. However, as shown in Fig. 7B, if the IoU overlaps vertically, then more than half of the IoU will overlap, even if the IoU value is high.

As shown in Table 2, YOLOv4 with an SPP structure yields the highest mAP of 91.69%. Overall, mAP drops sharply when the IoU_threshold is 0.6, but YOLOv4 exhibits the smallest drop. In Table 3, when the IoU_threshold is 0.5, it generally yields high performance, and when IoU_threshold is 0.6, the feed-eating behavior mAP drops the most significantly for YOLO v3. Because YOLOv4 learns pig features by subdividing them using SPP, the mAP drop for feed-eating behavior caused by predicting a binding box closer to the pig is smaller than those in the other algorithms [24]. In contrast, in the modified YOLOv3, many overlapping objects occur at the smallest feature size and the mAP drops sharply for feed-eating behavior. Pig behavior detection performs well if pigs do not overlap, but when overlap occurs, it is difficult to detect behaviors accurately because multiple pigs may be recognized as a single pig. Additional research is required to address this problem.
CONCLUSION
This study aimed to check and manage water and feed intake continuously to support pig health and weight gain. A decline in pig water and feed intake can be attributed to the sensory and organizational properties of feed, animal physiological conditions, breeding environment, and specification management. Therefore, it is possible to manage the health and weight of pigs by improving their environment to encourage or suppress intake through continuous monitoring. To detect pigs, YOLOv3, YOLOv4, and modified YOLOv3 models were adopted. When the IoU threshold was 0.5, the F1-Score and mAP were generally greater than 90%. Overall, YOLOv4 produced good results, but in terms of drinking water, the modified network that used an additional detection layer and the Mish function performed best. This indicates that pig detection performs best in an environment where pigs do not overlap. If a network adopts an SPP structure, horizontal overlap can be solved by predicting tight bounding boxes, but vertical overlap is difficult to solve. Therefore, if an additional detection layer is added to YOLOv3 to resolve overlapping pigs and instance segmentation is applied to a network with the Mish function, it will yield high performance, even in pens containing many pigs. Because instance segmentation only extracts the pixels of objects inside the bounding boxes of detected objects, it is possible to learn from multiple objects. If we solve the failure to detect pig behaviors caused by overlapping pigs in the future, we will be able to confirm the exact amounts of water and feed intake of pigs. Accurate intake analysis can support efficient feed distribution and the need to improve the environment and signals of abnormal health conditions can be identified immediately. This will increase pig productivity and help combat future food shortages.