
INTRODUCTION
Owing to the rich grasslands in the Inner Mongolia Autonomous Region (China), animal husbandry is an important part of the local economy, and its development is a leading concern in China [1]. Cattle breeding is a particularly important field in animal husbandry. With the expansion of breeding scale and the development of information technology, cattle breeding has gradually changed from a traditional cage-free model to a specialized cluster model [2]. Smart pasture could manage land and animals more effectively through automatic equipment and technology, and the data of individual animal could be collected, which contributes to improve farm animal welfare, reduce manpower, increase productivity, and boost profits [3,4]. The accurate monitoring of the behavior of individual animals plays an important role in assessing their physical health [5].
Rumination is a unique behavior observed in ruminants, such as cattle and sheep. Accurate monitoring of rumination time and frequency can help the farmer assess the physical health of the cattle, allowing sick cattle to receive treatment as soon as possible [6-8]. It can also help determine whether to modify ration particle size according to the amount of time each cow spends ruminating, thereby achieving precise feeding and increasing the revenue earned by herders [9,10]. There are older studies on the automatic monitoring of rumination, which are mainly divided into two categories: one category identifies rumination by fitting animals with contacting monitoring devices [11-15], while the other monitors the animals via visual rumination monitoring programs [16-20]. These wearable devices have been used for the automatic monitoring of cattle rumination, and the accuracy of such devices have met the basic commercial requirements the accuracy. Because all of them contact the body, it is more convenient to analyze videos and monitor rumination through visual rumination monitoring programs. With the development of artificial intelligence, contactless visual inspection using visual monitoring devices has recently gained much attention.
The farm environment is complex and the number of cattle captured in surveillance videos is unclear, for the realization of cow’s contactless rumination analysis, it is necessary to implement multi-object tracking using computer vision. A traditional object-tracking algorithm can be created by training a discriminative or generative model, such as Multiple Instance Learning [21], Track Learn Detect [22] and Discriminative Scale Space Tracker [23]. With the ongoing development of artificial intelligence, researchers more commonly apply deep learning to multi-object tracking, as with the Hierarchical Correlation Features-based Tracker [24], Accurate Tracking by Overlap Maximization [25], DeepSORT [26] and CenterTrack [27].
Some researchers have applied multi-object tracking algorithms to animal husbandry. Sun et al. proposed an algorithm for multi-object tracking loss correction based on Faster Region-based Convolutional Neural Networks (R-CNN) after observing that target-tracking frames can get lost while visually tracking pigs [28]. Zhang et al. proposed a robust online method of detecting and tracking multiple pigs, which, coupled with a CNN-based detector and a correlation filter-based tracker via a novel hierarchical data association algorithm [29]. Zhang et al. successfully tracked beef cattle in a real-time surveillance video by adding a long-short range context enhancement module (LSRCEM) to the You Only Look Once Version 3 (YOLOv3) algorithm and combining it with the Mudeep re-identification model. Before rumination could be identified, the cattle heads needed to be tracked. The methods described above track animals well [30].
The aforementioned object-tracking methods mainly tracked the whole body of animal, they are not suitable for head-tracking. Xu et al. used RetinaNet-based detection model for the detection of multi-view cattle faces [31]. The objective of this study was to find a new way to automatically monitor and analyse cattle rumination using visual rumination monitoring programs, with no physical contact. The cattle mouths need to be detected while detected cattle heads. So we used a multi-object tracking algorithm combined with YOLO and the kernelized correlation filter (KCF) for the tracking of cattle heads [32], and the mouths were detected by YOLOv4. When the cattle were ruminating, they were generally relaxed; their bodies were mostly stationary, with movement observed only in their lower jaws. Before examining the cattle for rumination, we tracked their heads via video, rather than their whole bodies. The parameters of the KCF trackers were set to achieve stable, automatic multi-object tracking of cattle heads. The rumination recognition algorithm was then constructed using the frame difference method and was used to identify rumination, as well as to calculate rumination time and number of chews for each cow. This study could provide a new no-contact method of automatically monitoring rumination in cattle, and provide valuable technical data for abnormal behavior analysis and precision livestock farming.
MATERIALS AND METHODS
The videos used in this experiment were captured at a cattle farm in Baotou, Inner Mongolia Autonomous Region, China, on October 11, 2020, when the temperatures were between 1 and 10 Celsius. The videos were manually filmed outside the fence with a high-definition video camera at a distance of about 4–8 m from the cattle. After screening, three stable videos showing multi-object rumination with the least amount of jitter were chosen, and these cows could be seen clearly in these videos. Each video included at least three cows and lasted 20 to 35 seconds, with a frame rate of 30 fps. Not all cattle in the videos were ruminating at the time of filming; some were turning head, lying and standing. The video statistics are shown in Table 1.
All three videos were numbered. The video time column shows the duration of each video. The cow numbers were obtained by numbering the cows during the detection stage, and were used to identify each cow. The rumination time and number of chews were obtained via human observation, and are shown in the last two columns of Table 1.
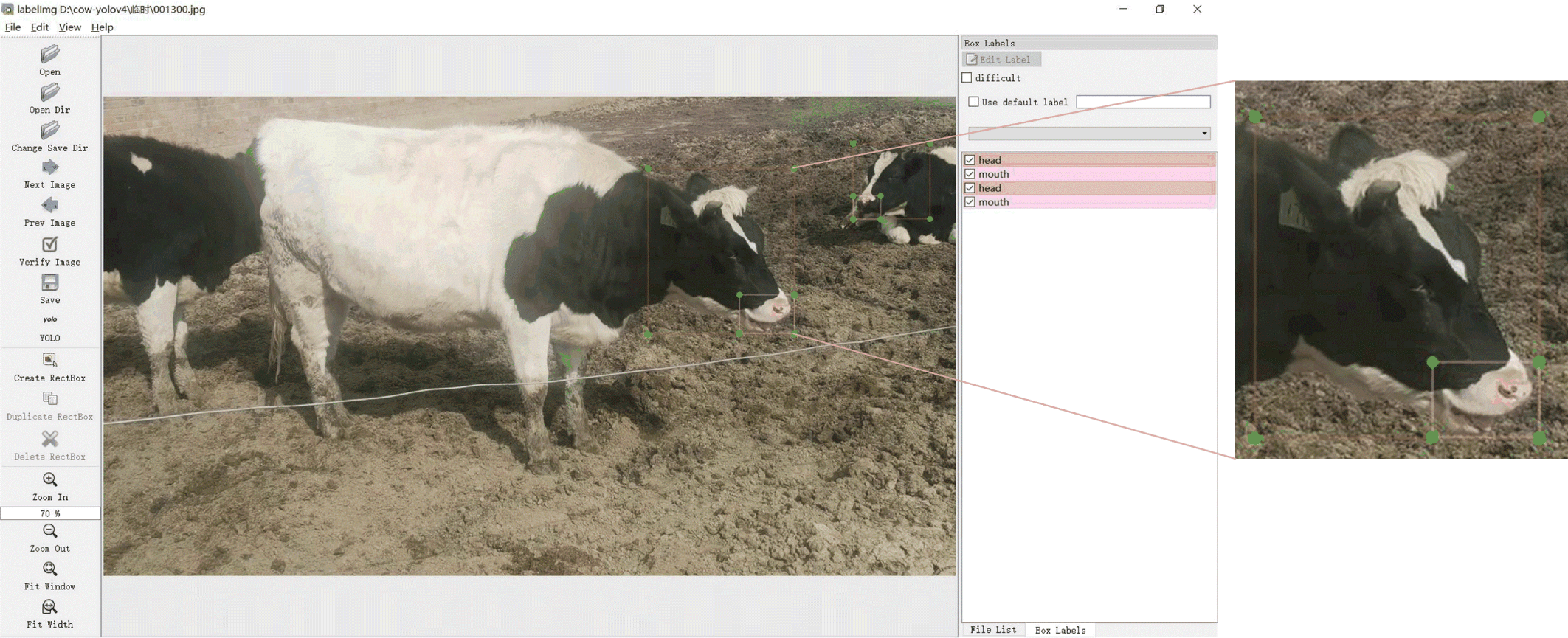
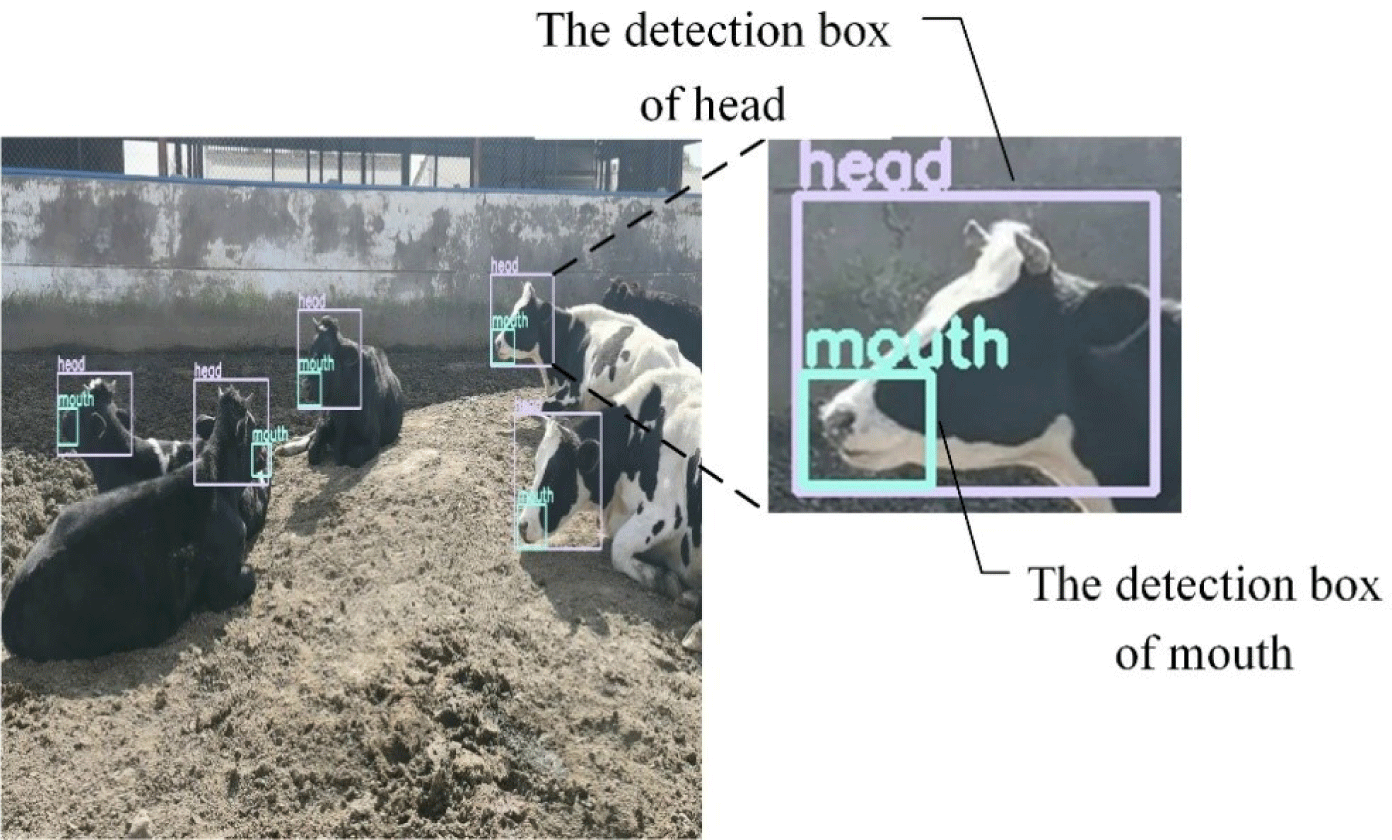
In any experiment where an object detection model needs to be trained, an object detection dataset should first be created. For this study, key frames were extracted from the captured videos and combined with cattle images provided by other re-searchers in the same group, resulting in a total of 1,000 images. The object detection dataset was created with the image-labelling software LabelImg [33], we drew the rectangular boxes of cattle heads and mouths in these images manually, and the corresponding label files were generated, the labeled image were shown in Fig. 1. The dataset consists of the image files and their corresponding label files. The images were then randomly divided into training and testing sets at a ratio of 9 : 1. The YOLOv4 object detection model was trained using these images, some of which are shown in Fig. 2.

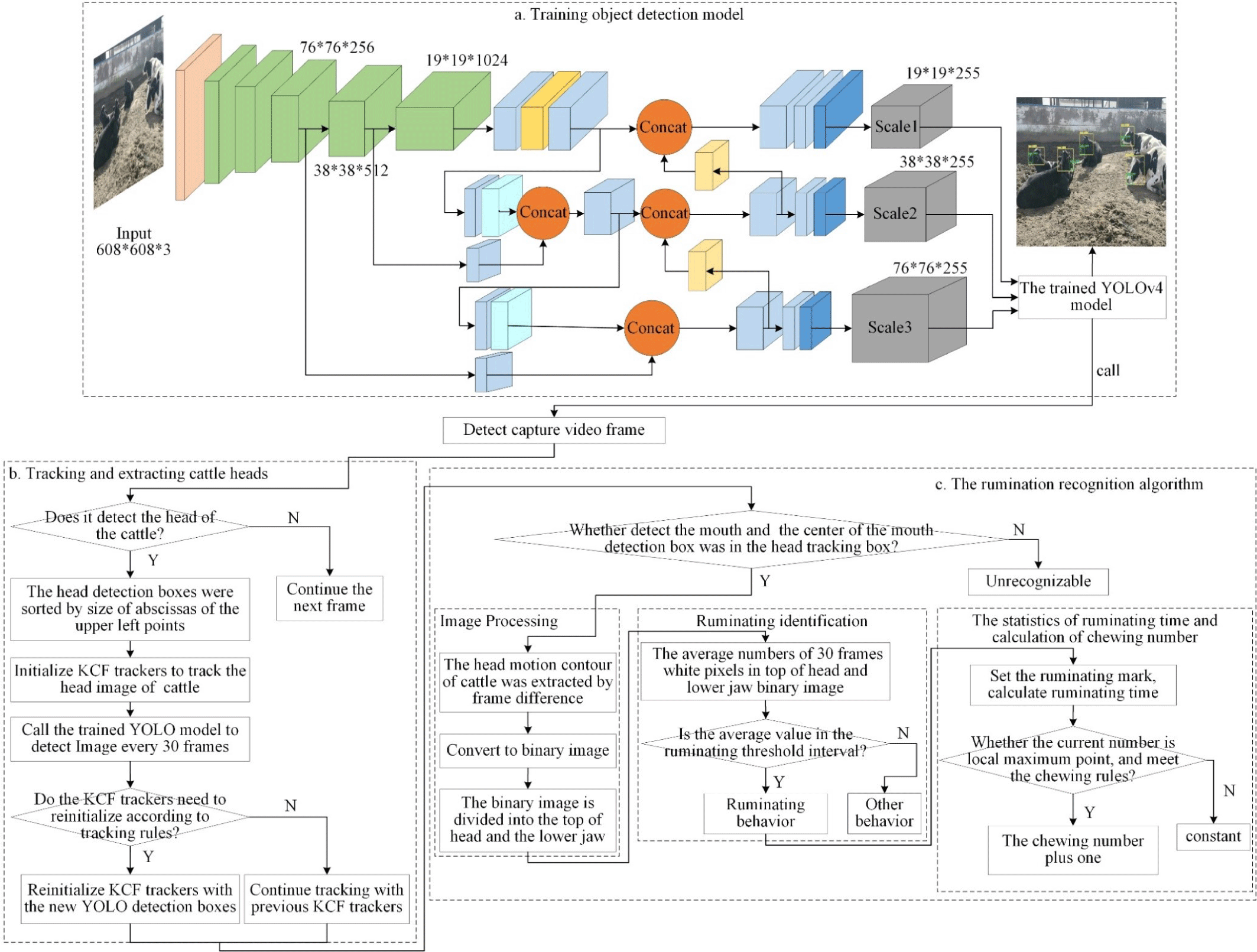
The overall technical program for multi-object cattle rumination identification is shown in Fig. 3. The main steps in identifying rumination were as follows:
-
Training the object detection model: The YOLOv4 model was trained using the previously prepared dataset, and the object detection model was obtained.
-
Tracking and extracting cattle heads: The head image of each cow in the video was obtained by combining the trained YOLOv4 model with the KCF tracking algorithm.
-
Constructing a rumination recognition algorithm specific to cattle: The rumination recognition algorithm was constructed using previous YOLOv4 object detection results and the frame difference method.
-
Multi-object cattle rumination identification: After head images were obtained for all cattle in the video, the rumination recognition algorithm was used to determine whether each cow was ruminating, rumination time, and number of chews.
YOLOv4 was chosen for object detection. The platform was Ubuntu 16.04.7 and the processor was an Intel(R) Core(TM) i9-9900K at 3.60GHz, with two 11GB NVIDIA GeForce GTX 2080Ti GPUs and 64GB RAM. The YOLOv4 model structure is shown in Figs. 3A and 4 shows some of the object detection results by the trained model.
Rumination is mainly a lower-jaw movement. Before rumination can be identified, head images must first be extracted. The algorithm created for this study used YOLO and KCF for multi-object cattle head tracking.
Henriques et al. proposed KCF, a discriminant object-tracking algorithm [34]. A discriminant classifier was trained with a given sample to determine if the tracked object was the target. We needed to select the target area in the image to initialize the KCF tracker. A large number of positive and negative samples were generated by cyclic shift sampling around the target area, and ridge regression was used to train the tracker. For each new frame, the tracker detected the patch at the previous position, and the target position was updated to the one that yielded the maximum value. Per the diagonalization of circulant matrices in the Fourier domain, this greatly reduced computation and improved operational speed to meet the real-time requirements.
The multi-object cattle-tracking algorithm flowchart is shown in Fig. 3B. The main steps were as follows:
-
Object detection: The first video frame was detected by calling the trained YOLOv4 model. If any cattle heads were detected, all detection boxes were sorted by the size of the abscissas of the upper left points, and this information was saved. If no heads were detected, we proceeded to the next frame, then the next, until the target was detected.
-
Create a multi-object tracker: A multi-object tracker, including multiple KCF trackers, was created. The number of KCF trackers matched the number of YOLO detection boxes. The KCF trackers were initialized according to the order of the YOLO detection boxes in step (1), then numbered.
-
Object tracking: When the KCF tracker was used to track a target, it was unable to adapt to scale changes or fast movements, so it was likely to lose the target. Therefore, the KCF tracking boxes were updated to YOLOv4 detection boxes in this study, and the cow id should be determined. Every 30 frames, the YOLOv4 model was called again to detect the image, and the cattle head detection boxes were obtained. The new YOLO detection boxes needed to be assigned the cow id number, and judged whether the KCF tracking boxes need to be reinitialized according to the tracking rules.
-
Tracking rules: The specific tracking rules about tracker reinitialization could be seen in Fig. 5. If the number of detected boxes was different than the number of KCF tracking boxes, the KCF trackers needed to be reinitialized. Otherwise, through calculating which KCF box had the minimum distance with the YOLO boxes, the YOLO boxes were assigned a corresponding id.
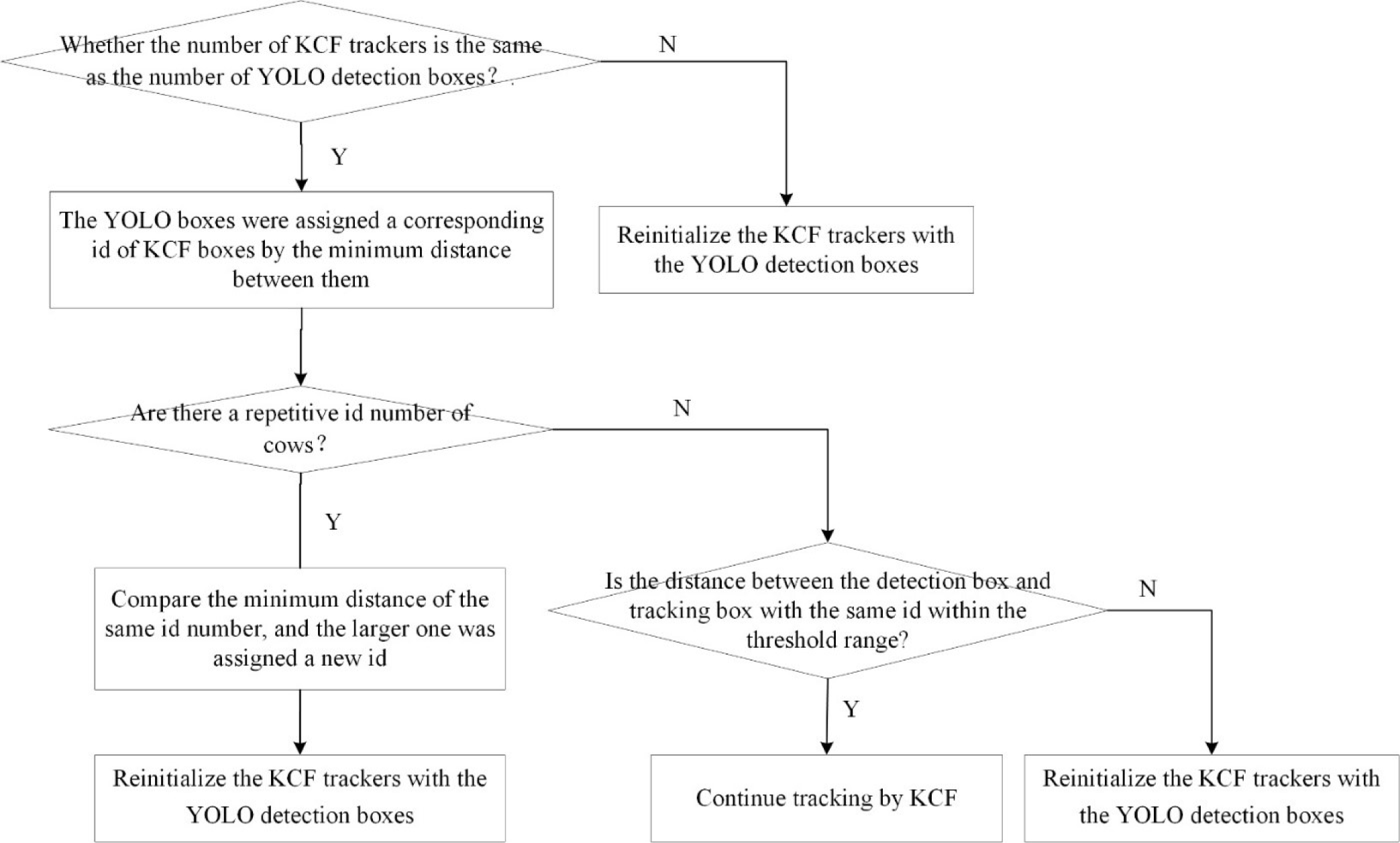
And we needed to judge whether there were repetitive id number of cows. If it was, the minimum distance of the same id number were compared, the larger one was assigned a new id, and the KCF trackers were reinitialized with the YOLO detection boxes. Otherwise, we would determine whether the distance between detection boxes and tracking boxes with the same id were all in the threshold range, as expressed as Equation 1.
(xy, yy) and (xk, yk) represent the coordinates of the YOLO detection box center point and the KCF tracking box center point respectively, and s is the threshold to determine the distance between the two center points.
If it was, the KCF trackers continued tracking the cow heads. Else, the KCF trackers were reinitialized with the YOLO detection boxes. The head images of each cow were extracted, then stored in their respective positions at a fixed size.
When we used video monitoring, we were able to see some cattle heads, but could not recognize any rumination processes due to object occlusion. Therefore, we needed to determine whether the rumination of the target cattle could be identified. When the trained YOLOv4 model was called, the mouths of the cattle were also detected, and the mouth detection boxes were stored. If no mouth was detected in the image, we were unable to identify rumination and therefore proceeded to the next frames until the mouth was detected. When a mouth was detected, we determined whether there was a center point in the mouth detection box. If there was a center point, we continued with the rumination identification of the target cow. If there was no center point, we determined that the rumination of the target cow could not be identified, and continued to the next.
Because any head movements were small when the cattle were ruminating, head motion contour images were extracted using the frame difference method and then transformed into binary images to reflect the size of the changes. We could see any changes in position through the number of white pixels in the binary images. The comparisons between ruminating and non-ruminating cattle can be seen in Fig. 6. If a cow was ruminating, its mouth would repeatedly open and close. The head changes are shown in Fig. 6A: the changes were mainly in the lower jaw, and movements at the top of the head were small. If the cow was doing something else, such as turning its head (as in Fig. 6B), the changes at the top of the head and around the lower jaw were large. If the cow was static, as in Fig. 6C, there was almost no variation in the head images. The top of the head and the lower jaw should change at the same time during rumination, unless the cattle are stationary. If the changes to the top of the head during rumination were smaller than a head turn, head-turning could be excluded from any changes noted to the top of the head, and rumination could be recognized.
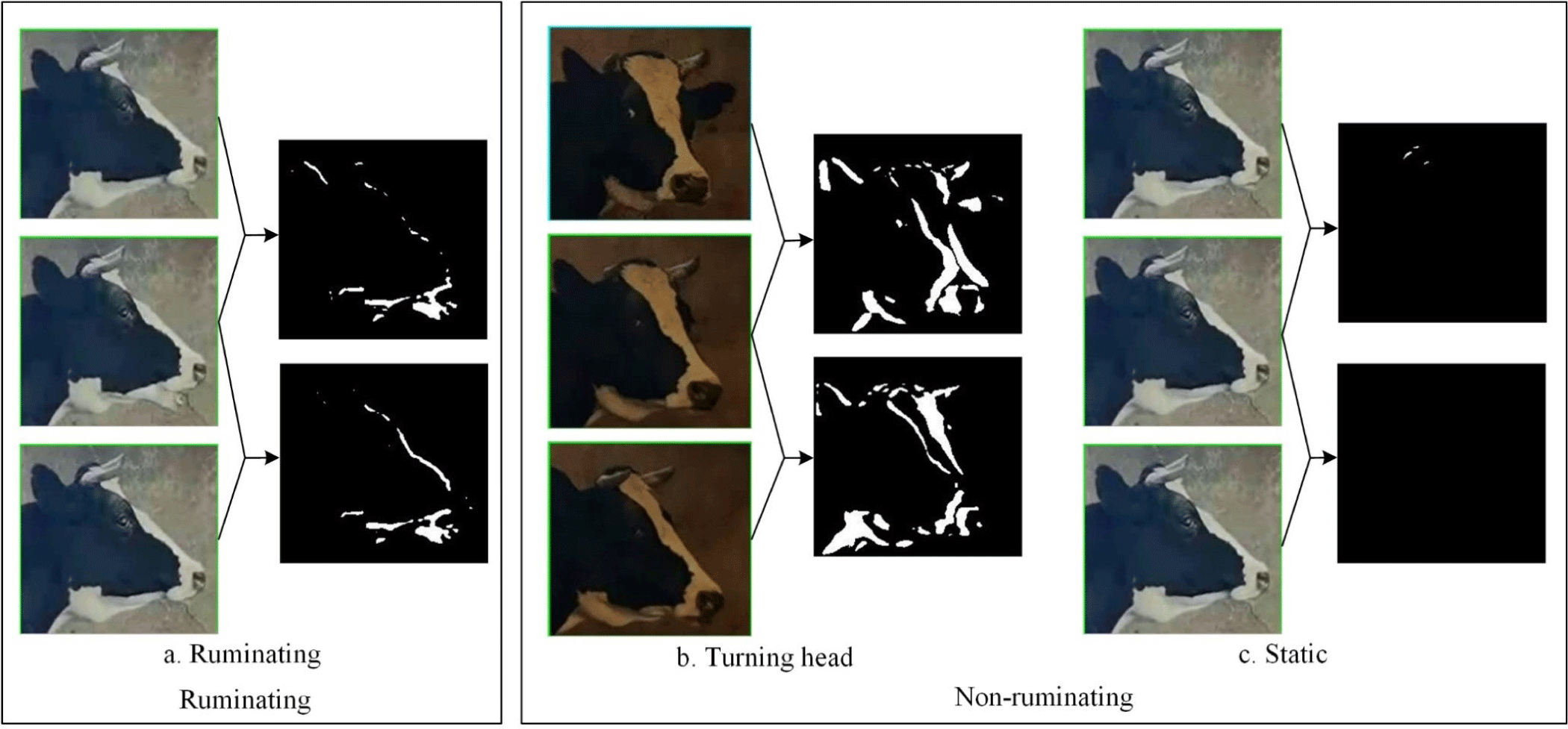
Therefore, the recognition algorithm described in this paper mainly used the frame difference method. After the head images of the target cattle were obtained, they were converted to grayscale, and any background noise was removed using median filtering. The head motion contour images were extracted using the frame difference method to differentiate adjacent frames of the same target cow’s head, then trans-formed into binary images. Because the main difference during rumination lies in the changes to the top of the head and the lower jaw, the tops of the cows’ heads and the lower jaws were separated at a ratio of 2 : 1 to better identify rumination, as shown in Fig. 7.

In this study, the white pixels in the two parts of the binary images were counted. The head changes seen in some adjacent video frames during rumination were small, so the number of white pixels in these video frames might have been too small to accurately recognize rumination. The average number of white pixels in continuing 30 frames showing the top of the head and the lower jaw (averti and averji) were calculated as rumination parameters, (averti and averji) were calculated as Equation 2.
ti is the number of white pixels in the top-of-the-head binary image of the first i frame, and ji is the number of white pixels in the lower jaw binary image of the first i frame.
Given that rumination mainly involved jaw movement, the number of white pixels at the top of the head and the lower jaw changed within a certain range. Because each camera angle was different, the rumination threshold interval changed for each video. About three to five seconds of each video was captured to determine the threshold value. From the shortened video, the minimum of averji was obtained as minj, the maximum of averji was obtained as maxj, the maximum of averti was obtained as maxt. When a cow was ruminating, the number of white pixels in the binary image of its jaw (averji) fluctuated within a certain range. However, the top of the head showed little to no movement, so the number of white pixels at the top of the head (averti) did not exceed the maximum. Therefore, the rumination threshold interval of the jaw was determined by minj and maxj, and the rumination threshold interval of the top of the head was determined by maxt. If the actual rumination parameters of the cattle fell within the rumination threshold, as shown as Equation 3. We determined that the target cow was ruminating, and set the rumination mark. Otherwise, the target cow was determined to be engaging in other activities.
If the rumination mark could be detected, the total number of rumination frames would be recorded. According to the relationship between the number of video frames, frame rate and time, as seen in Equation 4, the rumination time of the target cow would be calculated, and was displayed on the image.
Time is the rumination time of the target cow, Framecount is the number of video frames during which rumination takes place, and fps is the frame rate.
During rumination, the mouths of the cattle repeatedly opened and closed. The movement of the lower jaw showed some regularity; the number of white pixels in the binary images changed consistently, as seen in Fig. 8. The abscissa represented the number of video frames; the ordinate represented the number of white pixels in the lower jaw binary image. When the mouth opened, the number of white pixels gradually increased to the maximum, then reduced when the mouth closed.
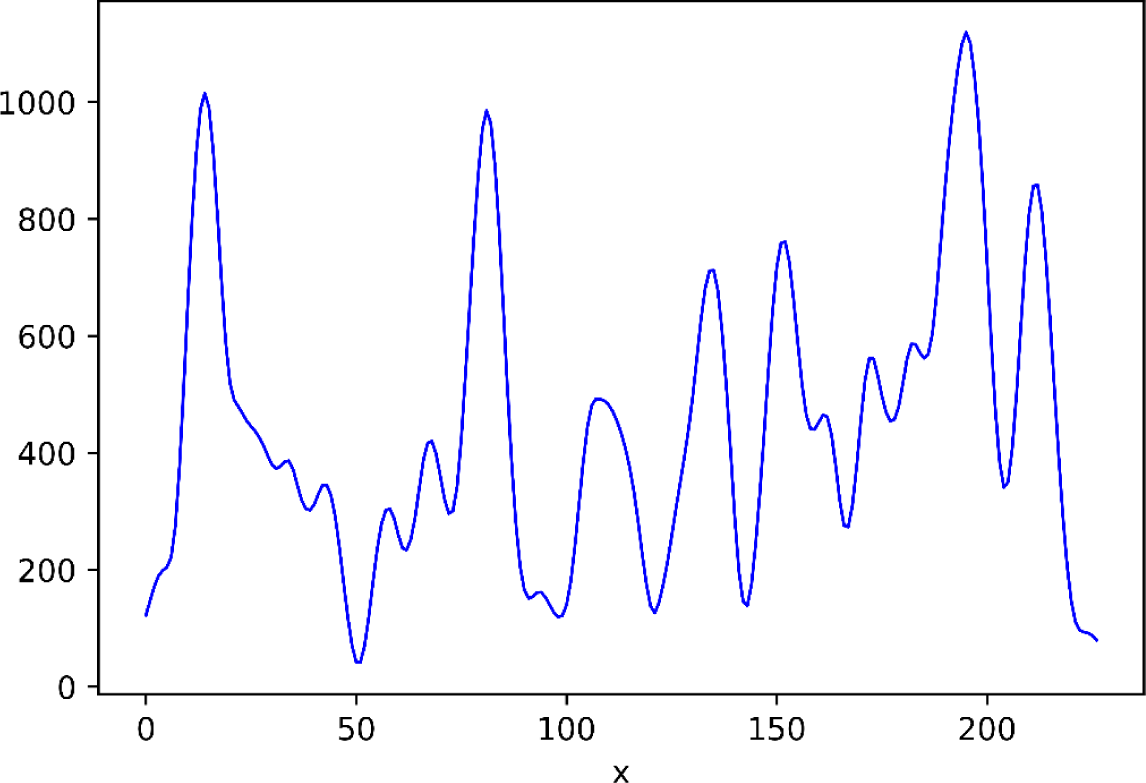
The number of chews during rumination was calculated through the number of local maximum points in the change curve. Generally, cattle take more than 0.8 s for every chew during rumination, and the usual video frame rate is 30. In order to reduce the errors introduced by camera jitter, the difference between the frame numbers for the local maximum point from the adjacent chewing frames should be greater than 24. The rumination time between two adjacent chewing frames should be greater than 0.8 s. The number of chews for the target cattle was calculated using these rules, and was displayed above the target cattle images.
Head images were obtained for all cattle using the above tracking algorithm. These images were then analysed by the above rumination recognition algorithm, which identified which cattle were ruminating. The rumination time and number of chews would be calculated and displayed over the corresponding head image.
RESULTS AND DISCUSSION
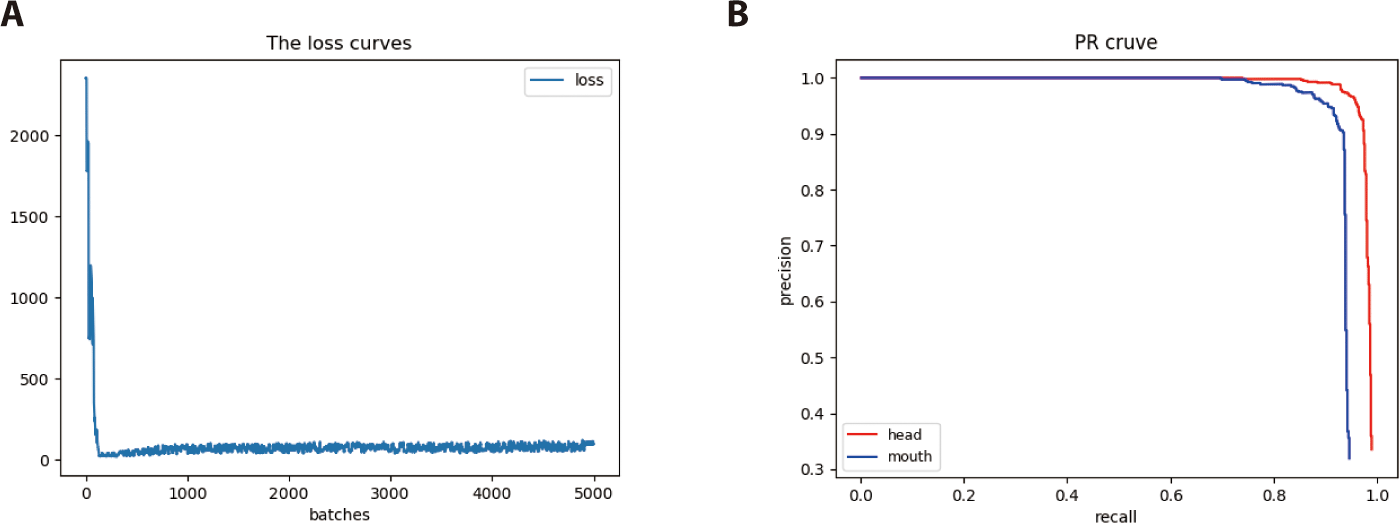
The YOLOv4 was trained to detect the head and mouth of cattle in video. The image dataset set 608 × 608 pixels was input, with the max batches of 5,000, learning rate of 1.5 × 10−3, decay of 5 × 10−5, momentum of 0.949. The loss curve of training was shown in Fig. 9A, with the increasing of training batches, the loss reduced and become stable gradually. And the Precision-Recall curve of trained YOLOv4 model was shown in Fig. 9B, the high area under the curve represents both high recall and high precision, where high precision relates to a low false positive rate, and high recall relates to a low false negative rate. The Precision-Recall curve shows that the trained model is returning accurate results, as well as returning a majority of all positive results. After training, the head’s average precision (AP) is 98.17%, the mouth’s AP is 93.60%, and mAP@0.50 is 95.9%. The object detection result was shown in Fig. 10, in the condition of dark light such as the second image in Fig. 10, the object could been still detected.

In previous researches, the mouth’s AP of cattle was 87.8% [19], our mouth’s AP was 93.6%, there is a little improvement, and the head’s AP of cattle was 99.8% [31], our head’s AP was 98.7%, which was a little lower than it, but according to the object detection result, the multi-object cattle heads and mouths could be detected well. And all tracking videos were converted into images, we checked them manually and couldn’t find the missing detected objects, so we thought the YOLO and KCF could be used in tracking heads of multi-object cattle.
The platform used for the identification and analysis of multi-object cattle rumination was Windows 10. The processor was an Intel(R) Core(TM) i7-7500U at 2.70 GHz, with a 2 GB Intel(R) HD Graphics 620 GPU and a 2 GB NVIDIA GeForce 920MX GPU, and 8 GB RAM.
The rumination detection result of rumination was shown in Fig. 11. Green boxes indicated that the cow was ruminating; red boxes indicated that the cow was doing something else, or that rumination could not be identified. In Fig. 11, the id represents the number assigned to the cow in this video, time represents total time spent ruminating, and chew represents number of chews.

The error in this study was obtained by comparing experimental results with human observation, as shown in Table 2. The error in rumination time and the error in number of chews were calculated as follows:
Stime is the rumination time determined through our algorithm, Atime is the rumination time determined through human observation, Vtime is video duration, Sfre is the number of chews determined through our algorithm, and Afre is the number of chews determined through human observation.
Although the cattle showed small head movements, such as raising or turning their heads, the top of head movement were larger than rumination, which would resulted in more white pixels, so the rumination could still be clearly identified. The test result shows that the overall average error in rumination time was 5.902%. The maximum error in rumination time was 19.048%, and there were three cows whose rumination time errors exceeded 10%. The following were three main reasons about large error: ① the fog produced by the cow’s breaths during cold weather; ② the tonguing behaviour was misidentified as ruminating; ③ the cameras sometimes took slightly shaking. In the future, in order to improve the recognition accuracy of cattle rumination, we can try to use deep neural network to solve the problems.
The overall average error in number of chews was 8.126%. The maximum error was 15.625%, and there were three cows whose errors exceeded 10%. And the primary chewing error factors were that the previous rumination identification error was large.
Compared with the previous visual studies [16,17,20], the accuracy of this paper were 91.874%, we could see a slightly drop of accuracy, but the rumination of multi-object cattle could be identified basically without manual operation. The proposed method can achieve end-to-end automatic rumination identification of cattle. Although there were some errors in the experiment, if the rumination time and number of chews were detected to be abnormal frequently, the videos would be stored, and the farmers would be received a reminder and check the health status of cattle, and sick cattle would receive treatment promptly. The algorithm could save lots of labor costs and provide some technical reference for the detection of abnormal behavior and remote diagnosis in smart pasture operations.
CONCLUSION
Developing a visual rumination monitoring program is significant to the realization of smart pasture, which could identify cattle rumination automatically with no contact, and reduce the damage of wearable devices for cattle. So the paper constructed a no-contact rumination identification algorithm, the rumination time and number of chews were calculated. The average error in rumination time was 5.902% and the average error in number of chews was 8.126%. The results indicated that the proposed algorithm could be used for monitoring rumination. But the identities of individual cattle might be not determined if the tracking objects were missed. In the future, the cattle identities could be determined with other technologies, such as cattle face detection, cattle texture detection and cattle re-identification. Additionally, the rumination time and number of chews for each cow could be stored individually, and we could analyze the cattle abnormality with them.