
INTRODUCTION
The complete cattle genome has been sequenced, and Illumina (San Diego, CA, USA) and Affymetrix (Santa Clara, CA, USA) have developed commercial single nucleotide polymorphism (SNP) chips that use chip-based array technology [1]. The development of SNP panels has enabled many studies, such as genome-wide association studies (GWAS) and best linear unbiased prediction (BLUP) studies [2]. Many genetic markers associated with objective breeding traits have been identified for marker-assisted selection [3]. Using a high-density SNP panel in a GWAS increases the probability of finding quantitative trait locus regions [4]. Improved high-density SNP panels also increase the accuracy of genomic breeding value estimations using genomic BLUP [5–8].
However, it is very difficult to genotype all animals in a population because of the cost of high-density chips. In addition, SNP panels for different platforms, which may differ in density or chip data versions, are not completely compatible. Imputation methods for converting from low- to high-density data are an alternative [9].
Genotype imputation refers to statistical inference of genotype and includes family and population-based methods. Family based methods require sufficient pedigree information to compare reference and test groups, so are difficult to apply when there is no pedigree information or insufficient pedigree depth [10,11]. Population-based methods predict low-density genotypes of animals by referring to a reference population genotyped at high density. This method uses a library and haplotype clustering to find the most appropriate haplotype and genotype [12–15]. Many factors affect the imputation accuracy of this method, including the reference population size, relationship between animals in the reference and test populations, minor allele frequency of the SNP to be imputed, proportion of missing genotypes on the low- and high-density panels, marker density, population structure, and the level of linkage disequilibrium (LD) [16]. Generally, family based methods aim to identify the animals to be sequenced, while population-based methods aim at imputation of the genotypes of unrelated individuals. Many studies have examined ways to increase imputation accuracy using population-based imputation software, such as fastPHASE [17], Beagle [18], Minimac [19], and findhap.f90 [20]. However, no studies have examined imputation accuracy in Hanwoo cattle according to the reference population size and marker density. Hanwoo cattle is a native taurine cattle breed in Korea and has been bred as a draft animal since 5,000 years ago. Over time, Hanwoo cattle have been bred for meat production and have become very popular despite high prices due to marbling fat, softness, juiciness, and unique flavor. [21]
Therefore, this study investigated the efficacy of genotyping by imputation of a high-density chip from a low-density one, according to the reference population size and marker density, and proposes an appropriate reference population size for high-quality imputation in Hanwoo cattle.
MATERIALS AND METHODS
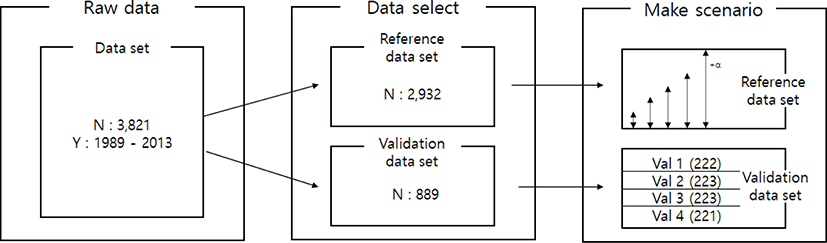
All the data-set (50K genotypes) used in this study was provided from the previous Research Project (BioGreen21, Hanwoo Research Institutes of National Institute of Animal Science, RDA) and current research project (Bridge Project of NIAS, RDA). To investigated imputation accuracy, the 3,821 animals were randomly selected from the population.
Genotype data was modified using GenomeStudio (Illumina) ver. 2.0 software with a genotyping module to fit the analysis software format: Illumina data file (.bsc) to genotype file format (.ped). We removed SNPs in unknown chromosomes and sex chromosomes for the next steps. The quality control procedure was performed using plink1.9 software [22]. The raw data has a 95.55% genotyping rate, so missing genotype data phasing was performed as a pre-imputation task for the imputation accuracy as a reference population. SNP data were subjected to strict quality control to minimize the impact of the imputation accuracy on genotyping error: minor allele frequency (0.01), genotyping call rate (0.9), missing individuals (0.1), Hardy-Weinberg equilibrium test p-value (0.0001). After quality control, a total of 38,933 SNPs were used for analysis. the number of SNPs on each chromosome before and after quality control is described in Table 1.
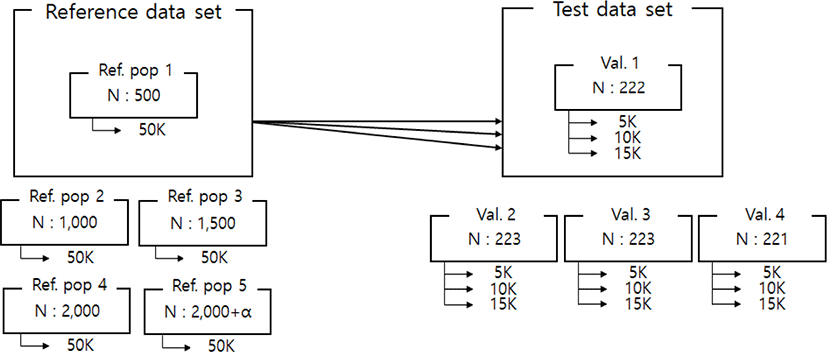
Imputation scenarios are set based on population size and marker density. The population size controls the size of the reference population, and the marker density controls the maker density of the test population. The test population was selected by the lowest birth year belonging to the data set. Thus, the test population consists of 889 animals, and these were divided into four validation sets. In the reference population, five reference populations were constructed. First, 500, 1,000, 1,500, and 2,000 animals are selected based on the individuals not included in the test population. In addition, 2,000 animals and the remaining test populations not included in each validation were included as reference groups to constitute over 2,000 (3,600) reference groups. When increasing the number of reference populations, the first 500 animals were randomly selected from the data set using the R program ver 3.6 [23], and another 500 animals were added from the remaining individuals. Thus, each scenario set is described in Table 2. and Fig. 1. In addition, three low-density SNP panels are created to use for validation marker density. Each SNP panel selected evenly spaced 5k, 10k, and 15k from a 50k Illumina chip, and the number and average distance of SNPs for each chromosome of these panels are described in Table 3. The test population data were analyzed using the generated low-density SNP panel information. A schematic diagram of the imputation scenario is illustrated in Fig. 2.
We analyzed the LD level, which is one of the factors affecting imputation accuracy. Because imputation uses haplotype information, imputation accuracy will decrease if the LD levels of the reference population and test population LD levels are different. LD value (r2) between SNPs within 1Mb distance was measured using plink1.9 software. This means that the maximum distance between the markers is 1Mb, and the average r2 value is estimated for each autosomal chromosome. The following formula is used for LD estimation [24].
Where, A1, A2, B1, and B2 are the alleles of SNP A and SNP B, and PA1, PA2, PB1, and P B2 are the corresponding allele frequencies. P A1B1 is the haplotype frequency of A1B1. The average LD levels of the reference and test populations used in all scenarios were analyzed whether they showed a similar pattern according to the SNPs’ distance. Also, the LD pattern was investigated in the test population according to the marker density (5k, 10k, 15k, and 50k).
Imputation of low-density (5k, 10k, 15k) data set to high-density (50k) genotypes was performed with the beagle program ver. 3.3 [25]. The beagle program, which is a population-based method, does not require pedigree information. The beagle program clusters haplotypes in each marker using a localized haplotype cluster model and then uses the Hidden Markov Model (HMM) to find the most probable haplotype based on the known genotype of each individual [26]. Therefore, collecting haplotype information and imputing un-genotyped SNP in the reference population is important for imputing validation data from low-density to high-density. The imputation was performed for each chromosome by pairing the reference data set and the validation data set in all scenarios. After imputation, the genotype was recorded for accuracy comparison, the AA, AB, and BB types were changed to 0, 1, and 2, respectively. The ratio was used as the imputation accuracy by direct genotype comparison of raw genotype and imputed genotypes. In addition, how the imputation accuracy changes are checked according to the minor allele frequency, reference population size, and marker density.
RESULTS
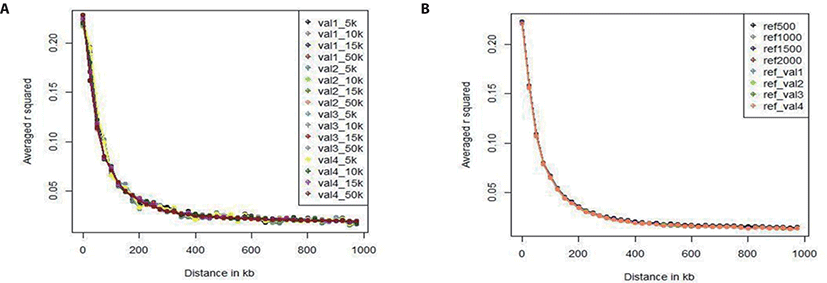
We investigated the LD pattern of all of our scenario sets (Fig. 3). Fig. 3A shows the LD pattern of the four validation sets according to marker density (5k, 10k, and 15k). In all validation sets, the overall LD estimation results showed very similar tendency; the level of LD decreases as the distance to the SNP increases. In each validation set, the LD pattern also differed slightly with the marker density, but the difference was less than 0.01. As there was no difference among the validation sets, the data were free from bias. Fig. 3B shows the LD pattern of the reference sets according to population size. The LD levels of the reference sets used in all scenarios were similar when the reference population size was 500, 1,000, 1,500, 2,000, or 3,600. Because the population size is larger than the validation set, the LD level does not change as the population size changes relative to the reference population. In addition, the LD level difference among the reference groups was smaller than the LD level difference among the validation sets. Comparing the validation set with the reference population set showed that the LD levels have similar patterns. In particular, the distance between SNPs can be divided into 0–20, 20–50, 50–100, 100–200, 200–500, 500–1,000 kb. Table 4 gives the number of SNP pairs in the reference and validation sets, and the average r-square (r2) values and deviations. As the distance between SNPs increased, the number of SNP pairs gradually increased; there were 750 pairs at 0–20 kb and 500,000 at 200–1,000 kb. The r2 value was 0.28 (0.32) at 0–20 kb and 0.02 (0.04) at 200–1,000 kb; it decreased rapidly up to the first 200 kb, and decreased slowly thereafter.
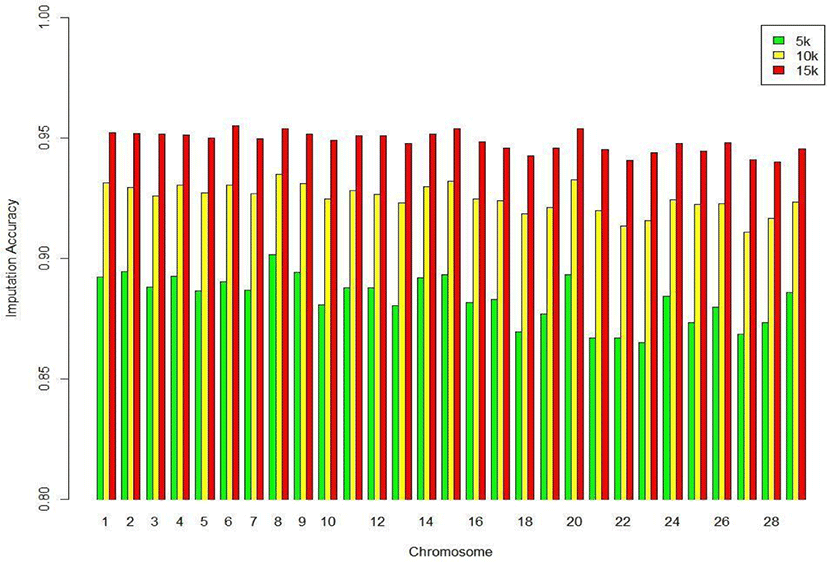
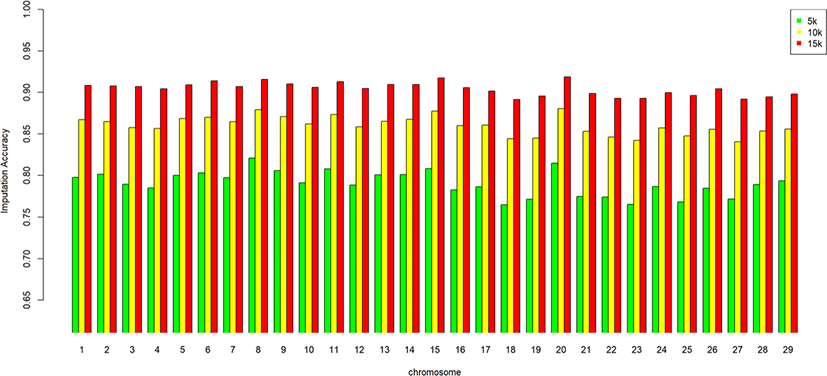
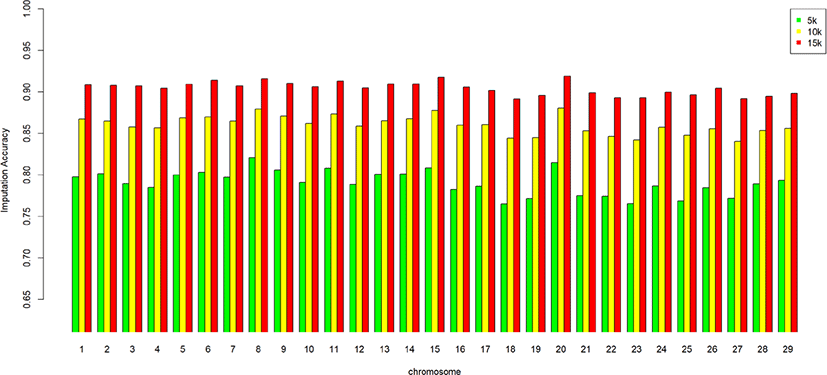
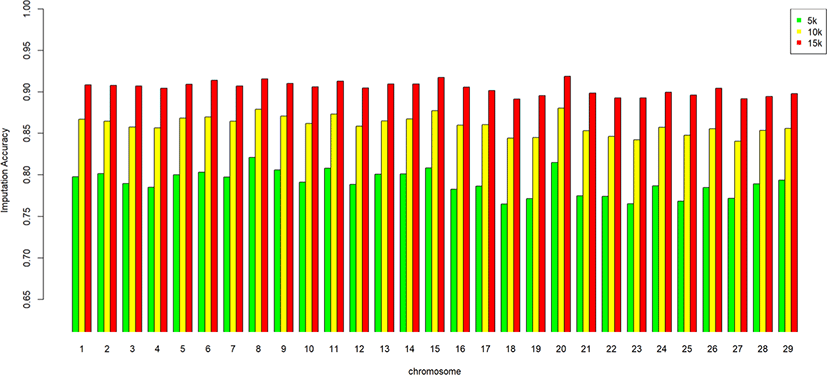
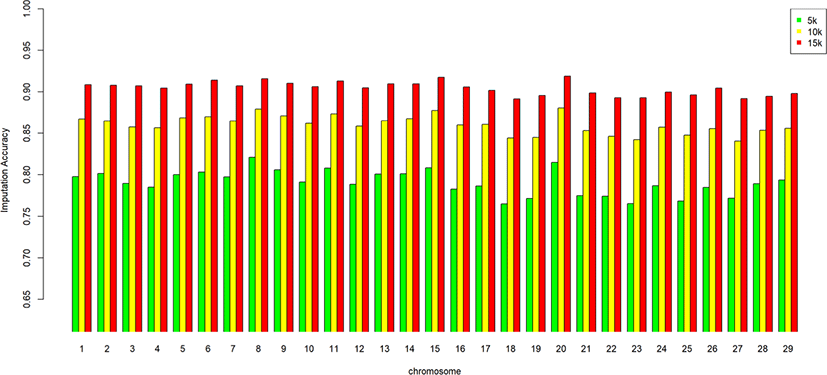
We assessed the genotype imputation accuracy according to the SNP panel density and reference population size. The average of the four validation sets represents the accuracy of each scenario. The lowest imputation accuracy was 79% with 5k marker density and a reference population of 500, and the highest accuracy was 97% with 15k marker density and a reference population over 2,000 (3,600). When we assessed the accuracy of each validation set, the maximum difference among the sets was about 4%, when the reference population size was 1,000 and the marker density 5k. The other scenarios had similar imputation accuracies. Fig. 4 plots the accuracy according to the marker density of each chromosome for a reference population of 1,500 (The imputation accuracies for each chromosome for reference population sizes 500, 10,00, 2,000, and over 2,000 are presented in Figs. 5–8); chromosome 21 show maximum variability in imputation accuracy. Fig. 9 plots the misplaced SNPs on the entire autosomal segment with markers of 5k (A), 10k (B), and 15k (C) from above and confirms the presence of several regions with poor imputation quality. Based on 0.75 as a threshold, 1275 SNPs were identified as substandard at 5k, 151 SNPs at 10k, and 65 SNPs were identified as substandard at 15k.
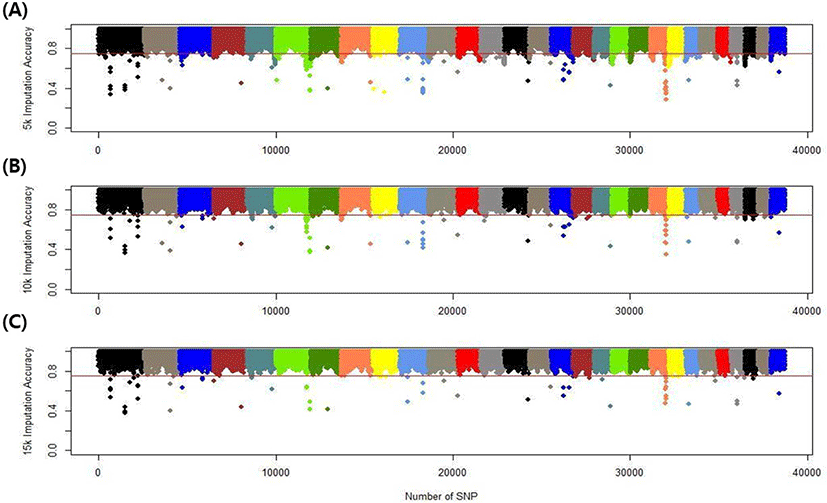
This study investigated the effect of marker density on imputation accuracy. Three low-density (5k, 10k, and 15k) datasets were used as marker data for validation and imputed to high-density (50k; 38,933). In the 5k marker dataset, the imputation accuracy was 0.793–0.929, with a 13.6% accuracy difference according to the reference population size. In comparison, in the 15k marker dataset, the imputation accuracy was 0.904–0.967, with a 6.3% accuracy difference according to the reference population size (Table 5). This shows that the higher the density of the validation set, the greater the imputation accuracy; moreover, the imputation accuracy difference according to reference population size is much greater at low than high density. The difference in imputation accuracy between 5k and 10k is also more significant than that between 10k and 15k. The efficiency of imputation increased with marker density in the validation set. Imputation took a comparatively long time when the marker density of the validation set was low. Time costs are not shown in this study.
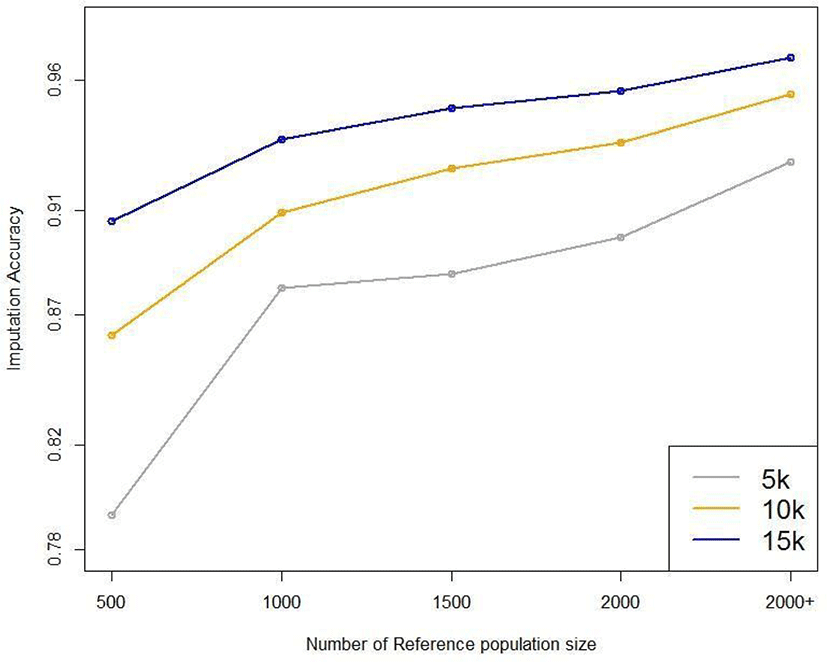
Five reference populations were examined: 500, 1,000, 1,500, 2,000, and 3,600. When selecting the animals for the reference population, we used random sampling based on birth year; the relatedness of the animals was not considered. Fig. 10 plots the average imputation accuracy according to reference population size and test data marker density. For the smallest reference population (n = 500), the imputation accuracy was 0.793–0.906, differing by 11.3% according to marker density. For the largest reference population (3,600), the imputation accuracy was 0.929–0.969, differing by 4% according to marker density (Table 5). These results show that the larger the reference population, the higher the imputation accuracy. Moreover, the difference in imputation accuracy according to marker density is much more significant with small reference populations. When the reference population in Hanwoo cattle exceeds 1,000, the average imputation accuracy exceeds 88%, even using 5 k SNP data (Fig. 10). The imputation efficiency increased with reference population size, and imputation took longer if the reference population was small.
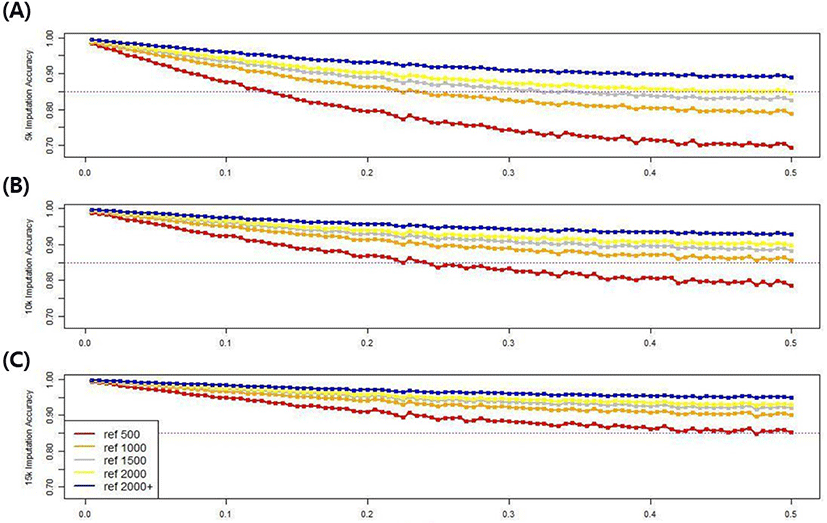
To investigate the effect of minor allele frequency, which affects imputation accuracy, the minor allele frequency of all SNPs was increased from 0 to 0.5 in 0.005 increments, with 100 groups in all scenarios. The imputation accuracy of each minor allele group based on population size and marker density was compared. Fig. 11 shows the imputation accuracy in five reference populations with three different marker densities up to 50k, according to the minor allele frequencies. The imputation accuracy was negatively related to the minor allele frequency, confirming that the imputation accuracy decreased as the minor allele frequency increased. Using the 5k marker data in the validation set, the 0.005 and 0.5 groups had accuracies of 98.3%–99.4% and 69.4%–88.9%, respectively, depending on the size of the reference group, and the difference in accuracy was 10.5%–28.9%. However, when the 15k marker data was used in the validation set, the 0.005 and 0.5 groups had respective accuracies of 99.3%–99.7% and 85.2%–94.9%, varying depending on the reference population size, and a 4.7%–14.1% accuracy difference. Therefore, as the marker density or reference population size increases, the difference in imputation accuracy decreases, even if the frequency of minor alleles increases. There was a clear distinction among scenarios when the imputation accuracy threshold was 85%. If a 15k marker density was used in all scenarios, the accuracy exceeded the threshold value.
DISCUSSION
In this study, we use Hanwoo genotype dataset from BioGreen 21 data set of National Institute of Animal Science, RDA, to generate scenario data for genotype imputation. The validation data were the data set of the youngest 889 animals; and these were divided into four validation sets. The others were used as a reference group to perform imputation using Beagle 3.3, a population-based method.
The imputation accuracy was examined by direct comparison between the true and imputed genotypes. We investigated LD in Hanwoo cattle because the population LD level affects the imputation accuracy. Uemeto et al. (2015) confirmed that Japanese black cattle had 0.1 LD (r2) when there was 200 kb between SNP pairs [27]. Using 16 Holstein breeds, Hoze et al. (2013) reported 0.2 LD (r2) when there was 100 kb between SNP pairs [28]. Thus, high LD means that the association between SNP markers is also high. This increases the probability of appropriate inference for closely located SNPs during imputation. Hanwoo cattle have a lower LD value than other cattle breeds and require a larger reference population to achieve high imputation accuracy.
Imputation accuracy of 95% in Japanese black cattle was obtained with reference populations greater than 400 [27]. In comparison, 90% imputation accuracy was obtained in Holstein cattle with reference populations greater than 300, and 95% imputation accuracy in Fleckvieh cattle with reference populations greater than 400 [29]. In Hanwoo cattle, the imputation accuracy was 88% at low-density (5k) for reference populations greater than 1,000, while it was the same as in Holsteins (where long chromosomes have greater imputation accuracy than short ones) [30].
Imputation accuracy is also influenced by the marker density of the validation data. In dairy cattle, the imputation accuracy of a reference population of 2,406 was 72%, 82%, 91%, 93%, and 97% at marker densities of 384, 768, 1,536, 2,480, and 6,177, respectively [31]. In this study, comparing the results of three low-density panels (5k, 10k, and 15k), the accuracy differed by up to 13.6% according to the marker density. We need to assess imputation accuracy according to the reference population size because, as the population size increases, the haplotype data increase along with the explanatory power of each haplotype, and the imputation error rate decreases. We assessed imputation accuracy according to five reference population sizes, to determine the effect of reference population size on imputation accuracy in Hanwoo cattle. When the imputation was performed with a reference population over 2,000 (3,600), the accuracy was 93% at the lowest density (5k), which is lower than in other breeds.
The minor allele frequency also negatively affects the imputation accuracy. Because imputation imputes missing values through a statistical method, a correct genotype is accidentally introduced more often at a low minor allele frequency [27,32]. However, as the marker density or reference population size increases, the difference in imputation accuracy decreases, even if the frequency of minor alleles increases.
In conclusion, the imputation accuracy difference was 6.3%–13.6% among marker densities, varying depending on the reference population size, and 4%–11.3% among reference population sizes, varying according to marker density. In Hanwoo cattle, a reference population of at least 1,000 is needed to obtain more than 88% imputation accuracy.